ML复习笔记
本来想写本周论文心得一类的,但是还是从简单的有构架的内容开始吧。大概会是字数最少的篇目,希望能尽可能地简洁表述(以及博客换了一下icon!变成史莱姆了!(不))
之前也有看过爱丁堡大学的公开课,因为是本科生的课程所以从基本的概念和概率开始讲,我校大概因为ML很出名所以即便不是CS和ML下属的ML入门课也是从线性代数开始单刀直入。(也可能是因为是研究生的课)不过还是把基础的概率讲一下(amioms of probability)
这次复习的:
1.基础概率论和PDF
2.高斯分布和相关parameter的变换
(由于博主不严谨所以全文的大小写通用,也就是X和x是一个东西,没有区别,土下座)
概率定理本身的规则其实很简单的
1.0< P <1 很好懂,概率只能在0%和100%之间,不存在200%这种文学夸张的内容。
2.P(true)= 1
3.P(false)= 0 第二三条更像是为了计算机使用而存在的定义,计算机的二进制1就是真,0为假,也就是很常见的Boolean
4.P(A∪B) = P(A) + P(B) - P(A∩B) 一些高中就学过的知识……两个集并集等于两个集相加后减去重复的交集部分。
然后就是由上述几条可以得知
5.P(A) = P(A∩B) + P(A∩~B),这里的~即为非,可以理解为整体里不是B的部分,而P(B) + P(~B) = 1。
到这里为止还是一切看着都很傻瓜www不过本来很多复杂的内容就是一些人在原有的基础定理上像是魔术师玩花活一样玩转出来新鲜但是越来越难懂的内容!
那接下来就是进一步,conditional probability,中文就叫条件概率。 表达是P(A|B), 假设A是头痛,~A是头不痛,B是感冒,~B是没感冒。那么这个表达的含义就是在感冒的一群人里有头痛这个症状的人所占的百分比。因此可知用之前的概率表达就是:
P(A|B) = P(A∩B) / P(B) 也就是经常会听到的Bayes Rule
然后从这个公式延伸出来可以得到:
P(A|B) = P(B|A) * P(A) / (P(B|A) * P(A) + P(B|~A) * P(~A))
其中分母就是P(A∩B),而分子也是之前提到的第5条,即为P(B)。这里看起来是把简单的公式完全复杂化了,但是这么做是因为现实应用里直接得到P(A∩B)和P(B)是比较少见的,而得到表达式里那些conditional probability则更常见,所以公式就变成了上述复杂的模样。
不过这里的例子只用了两个条件,现实里A可能并不是一个二极管,只存在有无,而是一个分类,像是奶茶的糖度不是加糖和不加糖,而是全糖,半糖,少糖,无糖,这样四种,于是表达也可以改成
P(A=无糖|B) = P(B|A=无糖) * P(A=无糖) / ∑P(B|A=糖分情况) * P(A=糖分情况)
这里分母就是4个项,有糖,半糖,少糖和无糖相加以后的概率总和。
或者另一种场合,除了AB外还有条件C,D。这时候表达使用不会变成P(A|B|C)这种,而是把两个条件合并,使用P(A|B∩C)这样。
下一个需要用到的概念是PDF,probability density function。
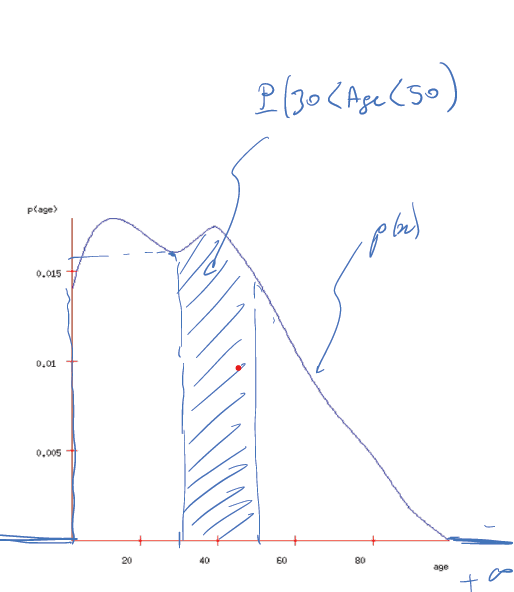
拿一张年龄分布图示意,这里每一个横轴表示的数字为年龄,但是对应的Y坐标数值并不是样本里随机拉一个人,然后这个人是这个年龄的可能性,因为单个Y数值在PDF里是没有任何含义的。那么这张图的概率在哪里呢?其实图上也画了,就是积分!这个函数从某一个X1到另一个X2的面积数值就是P(X1<x<X2)的概率,因此所有的函数下X面积加起来以后的总和是1,也就是∫P(x)dx=1。
从PDF衍生出的很重要的概念就是mean和variance,mean也叫做expected value,期待值,它们在高斯分布里非常重要。
mean = E[x] = ∫xP(x)dx 类似给每个数都加上了权重之后看数据均值。用上面的例子来说就是这个样本里随机拉一个人他最可能的年龄,就是这个E[x]
variance=∫(x-E[X])^2 * p(x)dx variance用于衡量这组数据分部,如果数据都很靠近均值,那么var就会很小,样本里的人都是同龄人;反过来数据极其分散,var就会很大,说明样本里都是忘年交。
如果吧variance开根号就会变成standard deviation,不过前者使用更多,因为方便微分,在之后很多操作里都会需要。
当你拥有了mean和var的时候,就可以——召唤神龙!(没有)
只是可以写一个高斯分布函数……这是一个非常常用的假设,应该说是自然界里的规律,简称盛极必衰。包括一门课的考试分部通常也是这样,虽然不是很明白为什么,可能是科学的尽头是玄学吧(瞎说的,不过是很多问题常见假设这点是真的)。
一维度的高斯分布公式如下,也称正态分布:
p(x) = [1/sqrt(2varpi)] * exp(-(x-E[x])^2/2*var)
同样,并不是所有的高斯分布都是一个变量x和一个结果p(x),而可能是三维四维一直上去的,假设三维的场合,就是两个变量x和y,结果z。可以想象一下珠穆朗玛峰,山的高度是z,然后在地图上的坐标用(x,y)表示。
除了x和y各自存在mean和var,大多数情况下x和y是相互关联的,或者说一定程度上绑定会相互影响,类似于不管你喜不喜欢总会存在的人际关系(?)。这时候就会有一个新的概念covariance,高斯分布的变量里mean是一个2x1的矩阵,而var变成4x4的矩阵,对角线上两项分别是x的var与y的var(数学中对角线指左上到右下角,这个对角线概念会在identity matrix再度出现),而剩下两个就xy的var与yx的var……没错,xy与yx是不一样的,虽然很多简单的场合是一样的但是存在两个不同的情况。简写cov[x,y], cov[y,x]
注意这时候原本的高斯函数里的各个变量就会变成矩阵,而不是原先的单个数字。虽然人的想象力也就到3维,用图形最多表示到4维,但是计算机里的矩阵可以到达非常高的维度,也就是只要计算机power足够,可以让好几万的变量abcdefg来构成一个高斯函数,这也是为什么数学会变得抽象的原因之一,因为人脑虽然无法想象但是还是可以算,理论上都是行得通的(。)
COV的表达倒是很简单,以bivariance(也就是只有xy的变量场合)来说,就是
COV[X,Y] = E[(X-E[X])(Y-E[Y])]=E[XY]-E[X]E[Y]
最后讲一下independent的概念,也就是x和y毫无关联,是八竿子打不着一辈子不会见面的陌生人模式。数学表达为 P(X∩Y)=P(X)*P(Y), 这时候COV(X,Y)就会变成0。然后conditional prob也会失去意义,因为P(A|B)=P(A),与B没有关系了。
(注意!COV=0并不是x和y independent的条件!COV=0但是x, y可以不是independent,不过反过来如果xy是independent那么COV一定是0)
以上。
大概讲了一些概率的基础概念,umm,没有案例讲真是挺无聊的,下次想想怎么多加点有趣的例子。不过,发现这种东西直接念比打字讲解更容易!写成博客模式反而很冗杂,或者下次试试直接改成一个小的topic来讲单元剧这样吧(摸鱼发言)